Summary
- A job is a chain of tasks, and reliability multiplies down - At 90% per task, a 10-step job finishes about 35% of the time, even though no single task got any harder
- AI is reliable on short, defined tasks - METR measured near 100% success on tasks under four minutes, and under 10% on tasks past four hours
- Structure beats autonomy - Anthropic’s playbook for agents favors workflows of predefined steps, because a smaller task is an easier task
- Tallyfy gates each task so the job holds - Define it, assign it to a person or an AI, check it, then hand off. Model your own job
Everyone is trying to hand AI a job. The smarter move is to hand it a task.
That distinction decides whether your AI rollout works, so it’s worth being precise. A task is one defined unit of work. Draft this email. Check this invoice against the purchase order. A job is a chain of those tasks, strung end to end, that adds up to an outcome: onboard the client, close the books, run payroll. AI is really good at the first kind. It’s shaky at the second. And the reason isn’t some deep limit of the models. It’s arithmetic.
Why does a ten-step job become a coin flip?
Because reliability multiplies, and multiplication of numbers under one only goes one direction.
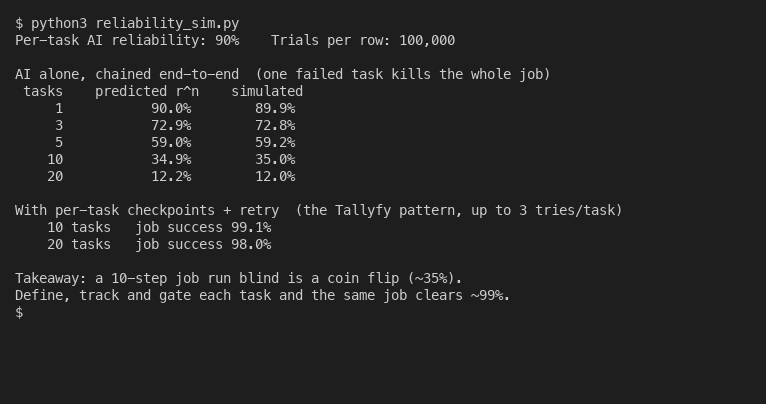
Say an AI does each task in a job at 90% reliability. Pretty good for one task. But the whole job only finishes if every task in the chain succeeds, so you multiply: 0.90 by itself, once per task. Three tasks and you are at roughly 73%. Ten tasks lands near 35%. Twenty tasks slides past 12%. Drag the sliders below and watch it fall. The model never got worse at any single step. The chain did the damage.
See the chain collapse
90% per task, 10 tasks in a row, is about 35%. A 10-step job done blind is worse than a coin flip.
Open the full reliability toolThat is the whole problem in one line, and it sits underneath most of the AI and future-of-work debate.
The measurements back it up. METR, the evaluation lab, found that frontier models hit almost 100% success on tasks a human could do in under four minutes, and under 10% on tasks that stretch past four hours. Short and defined: reliable. Long and open ended: not yet, and maybe not for a while. The thing is, most real jobs are the long kind, which is exactly why pointing an agent at a whole job and walking away tends to disappoint.
Define the task before you hand it to AI
Economists have known the unit was the task for a long time, mind you. The task based view of automation from Daron Acemoglu and Pascual Restrepo treats technology as something that acts on specific tasks inside a job, never the whole job in one go. A role is a basket of tasks. Machines take some tasks, people keep others, and new tasks show up. “Job” is an HR word. “Task” is the real economic unit, and it always has been.
The engineering view lands in the same place. Anthropic’s guidance on building effective agents describes the reliable pattern as a workflow, where “LLMs and tools are orchestrated through predefined code paths,” and recommends you “trade off latency for higher accuracy, by making each LLM call an easier task.” Smaller task, higher hit rate. That is not a workaround. That is the design.
So what makes a task AI ready? Four things, basically. A clear input. A clear definition of done. One owner, whether that is a person, an AI agent, or a rule. And a check before the next task starts. Get those right and AI has something it can actually finish. Skip them and you have handed a model a vague job and crossed your fingers. In the age of AI, defining the work is not the boring prerequisite. It is the part that decides if any of this pays off.
This is the whole reason we built Tallyfy the way we did. You document a process once as a sequence of defined tasks. Each task gets an owner and a deadline. Then you run it, with people and AI working the steps and the system tracking every status in real time. The recipe comes first. The AI second.
Run the proof yourself
The calculator uses plain probability, so a fair question is whether the math is hiding something. It is not, and you can check. Here is a short Monte Carlo that simulates actual coin flips per task across 100,000 trials. The simulated job success rate lands right on the predicted r to the power of n. It is seeded, so you will get the same numbers.
import random
random.seed(42)
TRIALS = 100_000
def chain_success(n, r, trials=TRIALS):
# Autonomous chain: the job succeeds only if all n tasks succeed
wins = 0
for _ in range(trials):
if all(random.random() < r for _ in range(n)):
wins += 1
return wins / trials
def gated_success(n, r, attempts=3, trials=TRIALS):
# Gated chain: each task gets up to attempts tries before the job fails
wins = 0
for _ in range(trials):
ok = all(any(random.random() < r for _ in range(attempts)) for _ in range(n))
wins += 1 if ok else 0
return wins / trials
R = 0.90
for n in (1, 3, 5, 10, 20):
print(f"{n:>2} tasks predicted {R**n:>6.1%} simulated {chain_success(n, R):>6.1%}")
print(f"gated 10 tasks: {gated_success(10, R):.1%}")Run it and you will see the chained numbers collapse while the gated number holds near 99%. You can download the full script or play with the inputs in the full calculator.
What a task-first rollout looks like
Here is where the gated number earns its keep. A control layer does the one thing a bare chain cannot: it checks each task before the next one starts, and re-runs the ones that miss. With up to three tries per task, a 90% task effectively clears 99.9%, so even a twenty-task job stays near 98%. Same model. Same per-task reliability. The only change is structure.
That gap explains a lot of the wreckage out there. Gartner expects more than 40% of agentic AI projects to be canceled by the end of 2027, and the common thread is teams aiming an agent at a whole messy job with nothing underneath it. No defined tasks. No checkpoints. No owner when a step goes sideways. It was never going to hold.
The fix is not a smarter model. It is giving people and AI a process to follow, where every task is defined, tracked, and gated, and a human stays accountable at the points that matter. That is the missing infrastructure for useful AI, and it is a no brainer once you have seen the math. We watched this play out while building the Tallyfy MCP server: an agent nails a single, well scoped tool call and stumbles the moment you ask it to carry an eight step process on its own. Give it one task at a time, with a check between each, and the same agent becomes genuinely useful.
If you are rolling out AI, start by writing down what a “task” means in your shop. Not a job. Not a project. One defined unit of work, with an owner and a finish line. Then automate that. For more on why undefined processes break under AI, see clean up your processes before you add AI, and for the agent side of this, why your AI agent needs a workflow engine. When you are ready to turn a fragile job into reliable tasks, start free.
